I1215 16:38:23.359299 2052022 docker_service.go:274] Setting cgroupDriver to cgroupfs I1215 16:38:23.359435 2052022 kubelet.go:642] Starting the GRPC server for the docker CRI shim. I1215 16:38:23.359456 2052022 docker_server.go:59] Start dockershim grpc server ...
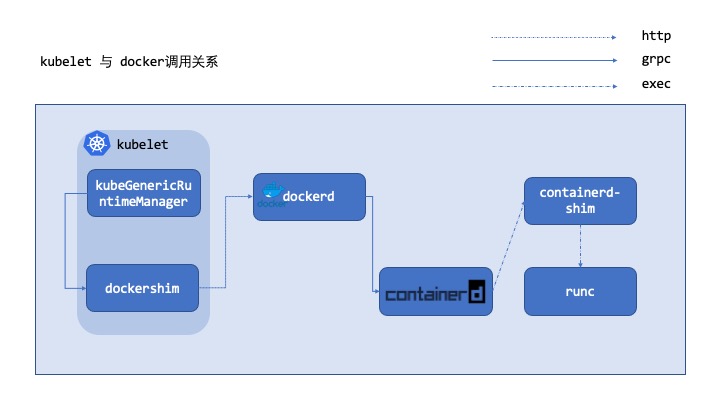
调研社区文档发现,dockershim 之所以被提出是为了解决 kubernetes 开发者面临多个runtime都要接入kubernetes导致调用运行时的相关代码接口不稳定的问题。 开发者引入一个抽象层对上屏蔽底层的runtime实现差异,这个抽象层称为CRI, 这里的 dockershim 就是基于 docker 二次封装的一个 CRI 实现。 shim 这个单词的由来可以从 wiki 上查到 an application compatibility workaround。
// SyncPod syncs the running pod into the desired pod by executing following steps: // // 1. Compute sandbox and container changes. // 2. Kill pod sandbox if necessary. // 3. Kill any containers that should not be running. // 4. Create sandbox if necessary. // 5. Create ephemeral containers. // 6. Create init containers. // 7. Create normal containers. func(m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) { // Step 1: Compute sandbox and container changes. podContainerChanges := m.computePodActions(pod, podStatus) // 还是声明式 api 模型,将操作序列化 ... // Step 2: Kill the pod if the sandbox has changed. if podContainerChanges.KillPod { ... killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil) ... // 删除一下无关紧要的代码,不影响主线逻辑 } else { // Step 3: kill any running containers in this pod which are not to keep. for containerID, containerInfo := range podContainerChanges.ContainersToKill { klog.V(3).Infof("Killing unwanted container %q(id=%q) for pod %q", containerInfo.name, containerID, format.Pod(pod)) killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name) result.AddSyncResult(killContainerResult) if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil { ...// 一些在运行,但是应该被删除的 container 处理逻辑, } } } ... // Step 4: Create a sandbox for the pod if necessary. podSandboxID := podContainerChanges.SandboxID if podContainerChanges.CreateSandbox { ... createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod)) result.AddSyncResult(createSandboxResult) podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt) // 这个函数是我们关注的核心,准备 pod 的沙盒,如何在 sandbox 中调用 CNI 设置网络/存储等 ... // 删除一下错误处理,事件的逻辑,网络相关,不影响启动一个不使用网络的 container 😄 // Get podSandboxConfig for containers to start. configPodSandboxResult := kubecontainer.NewSyncResult(kubecontainer.ConfigPodSandbox, podSandboxID) result.AddSyncResult(configPodSandboxResult) podSandboxConfig, err := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt) if err != nil { message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err) klog.Error(message) configPodSandboxResult.Fail(kubecontainer.ErrConfigPodSandbox, message) return }
// Helper containing boilerplate common to starting all types of containers. // typeName is a label used to describe this type of container in log messages, // currently: "container", "init container" or "ephemeral container" start := func(typeName string, container *v1.Container)error { startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name) result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, container, podStatus, backOff) if isInBackOff { startContainerResult.Fail(err, msg) klog.V(4).Infof("Backing Off restarting %v %+v in pod %v", typeName, container, format.Pod(pod)) return err }
klog.V(4).Infof("Creating %v %+v in pod %v", typeName, container, format.Pod(pod)) // NOTE (aramase) podIPs are populated for single stack and dual stack clusters. Send only podIPs. if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, podIPs); err != nil { // 创建 cotnainer 和 启动 container 是两回事,创建说的是准备好相关底层文件资源,启动就是以进程形式在 OS 可见,具体还要看底层运行时是如何实现的。 // .. 删除了一部分错误处理的逻辑 // Step 5: start ephemeral containers // 这部分逻辑非主线
// Step 6: start the init container. if container := podContainerChanges.NextInitContainerToStart; container != nil { // Start the next init container. if err := start("init container", container); err != nil { return }
// Successfully started the container; clear the entry in the failure klog.V(4).Infof("Completed init container %q for pod %q", container.Name, format.Pod(pod)) }
// Step 7: start containers in podContainerChanges.ContainersToStart. for _, idx := range podContainerChanges.ContainersToStart { // 就是业务的 container start("container", &pod.Spec.Containers[idx]) // start 可以前面看到定义 start := func(typeName string, container *v1.Container) }
// RunPodSandbox creates and starts a pod-level sandbox. Runtimes should ensure // the sandbox is in ready state. func(r *RemoteRuntimeService) RunPodSandbox(config *runtimeapi.PodSandboxConfig, runtimeHandler string) (string, error) { // Use 2 times longer timeout for sandbox operation (4 mins by default) // TODO: Make the pod sandbox timeout configurable. ctx, cancel := getContextWithTimeout(r.timeout * 2) defer cancel()
// RunPodSandbox creates and starts a pod-level sandbox. Runtimes should ensure // the sandbox is in ready state. // For docker, PodSandbox is implemented by a container holding the network // namespace for the pod. // Note: docker doesn't use LogDirectory (yet). func(ds *dockerService) RunPodSandbox(ctx context.Context, r *runtimeapi.RunPodSandboxRequest) (*runtimeapi.RunPodSandboxResponse, error) { config := r.GetConfig()
// Step 1: Pull the image for the sandbox. image := defaultSandboxImage // 这里就是 Google 的那个 sandbox 的 image podSandboxImage := ds.podSandboxImage iflen(podSandboxImage) != 0 { image = podSandboxImage }
// NOTE: To use a custom sandbox image in a private repository, users need to configure the nodes with credentials properly. // see: http://kubernetes.io/docs/user-guide/images/#configuring-nodes-to-authenticate-to-a-private-repository // Only pull sandbox image when it's not present - v1.PullIfNotPresent. if err := ensureSandboxImageExists(ds.client, image); err != nil { returnnil, err }
// Step 2: Create the sandbox container. if r.GetRuntimeHandler() != "" && r.GetRuntimeHandler() != runtimeName { returnnil, fmt.Errorf("RuntimeHandler %q not supported", r.GetRuntimeHandler()) } createConfig, err := ds.makeSandboxDockerConfig(config, image) if err != nil { returnnil, fmt.Errorf("failed to make sandbox docker config for pod %q: %v", config.Metadata.Name, err) } createResp, err := ds.client.CreateContainer(*createConfig) // 这里的创建 sandbox 是备好 container 需要底层资源 if err != nil { createResp, err = recoverFromCreationConflictIfNeeded(ds.client, *createConfig, err) }
if err != nil || createResp == nil { returnnil, fmt.Errorf("failed to create a sandbox for pod %q: %v", config.Metadata.Name, err) } resp := &runtimeapi.RunPodSandboxResponse{PodSandboxId: createResp.ID}
ds.setNetworkReady(createResp.ID, false) deferfunc(e *error) { // Set networking ready depending on the error return of // the parent function if *e == nil { ds.setNetworkReady(createResp.ID, true) } }(&err)
// Step 4: Start the sandbox container. // Assume kubelet's garbage collector would remove the sandbox later, if // startContainer failed. err = ds.client.StartContainer(createResp.ID) // 前面准备好 container 这里才去启动,具体怎么启动 kubelet 并不关心 if err != nil { returnnil, fmt.Errorf("failed to start sandbox container for pod %q: %v", config.Metadata.Name, err) }
// 删除了一下网络和安全相关代码和核心流程无关
// Step 5: Setup networking for the sandbox. // All pod networking is setup by a CNI plugin discovered at startup time. // This plugin assigns the pod ip, sets up routes inside the sandbox, // creates interfaces etc. In theory, its jurisdiction ends with pod // sandbox networking, but it might insert iptables rules or open ports // on the host as well, to satisfy parts of the pod spec that aren't // recognized by the CNI standard yet. cID := kubecontainer.BuildContainerID(runtimeName, createResp.ID) networkOptions := make(map[string]string) if dnsConfig := config.GetDnsConfig(); dnsConfig != nil { // Build DNS options. dnsOption, err := json.Marshal(dnsConfig) if err != nil { returnnil, fmt.Errorf("failed to marshal dns config for pod %q: %v", config.Metadata.Name, err) } networkOptions["dns"] = string(dnsOption) } // CRI 调用 CNI 来设置 POD 的基础网络 err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations, networkOptions)
func(s *containerRouter) postContainersStart(ctx context.Context, w http.ResponseWriter, r *http.Request, vars map[string]string) error { // If contentLength is -1, we can assumed chunked encoding // or more technically that the length is unknown // https://golang.org/src/pkg/net/http/request.go#L139 // net/http otherwise seems to swallow any headers related to chunked encoding // including r.TransferEncoding // allow a nil body for backwards compatibility
// 移除 http 检查相关逻辑,哪些不影响核心 if err := s.backend.ContainerStart(vars["name"], hostConfig, checkpoint, checkpointDir); err != nil { // here ...
// containerStart prepares the container to run by setting up everything the // container needs, such as storage and networking, as well as links // between containers. The container is left waiting for a signal to // begin running. func(daemon *Daemon) containerStart(container *container.Container, checkpoint string, checkpointDir string, resetRestartManager bool) (err error) { start := time.Now() container.Lock() defer container.Unlock() // 删除错误处理与一下防御编程
// NewContainer will create a new container in container with the provided id // the id must be unique within the namespace func(c *Client) NewContainer(ctx context.Context, id string, opts ...NewContainerOpts) (Container, error) { ctx, done, err := c.WithLease(ctx) if err != nil { returnnil, err } defer done(ctx)
bundle, err := newBundle(id, // newBundle creates a new bundle on disk at the provided path for the given id filepath.Join(r.state, namespace), filepath.Join(r.root, namespace), opts.Spec.Value) if err != nil { returnnil, err } deferfunc() { if err != nil { bundle.Delete() } }()
// ShimLocal is a ShimOpt for using an in process shim implementation shimopt := ShimLocal(r.config, r.events) if !r.config.NoShim { // 在正常的逻辑会命中这里,我们使用了 shim var cgroup string if opts.TaskOptions != nil { v, err := typeurl.UnmarshalAny(opts.TaskOptions) if err != nil { returnnil, err } cgroup = v.(*runctypes.CreateOptions).ShimCgroup } exitHandler := func() { log.G(ctx).WithField("id", id).Info("shim reaped") t, err := r.tasks.Get(ctx, id) if err != nil { // Task was never started or was already successfully deleted return } lc := t.(*Task)
log.G(ctx).WithFields(logrus.Fields{ "id": id, "namespace": namespace, }).Warn("cleaning up after killed shim") if err = r.cleanupAfterDeadShim(context.Background(), bundle, namespace, id, lc.pid); err != nil { log.G(ctx).WithError(err).WithFields(logrus.Fields{ "id": id, "namespace": namespace, }).Warn("failed to clean up after killed shim") } } shimopt = ShimRemote(r.config, r.address, cgroup, exitHandler) // 这里目前只是构建好了 shimopt 这个函数,目前还没有真的调用 }
// Create a new initial process and container with the underlying OCI runtime func(s *Service) Create(ctx context.Context, r *shimapi.CreateTaskRequest) (_ *shimapi.CreateTaskResponse, err error) { var mounts []proc.Mount for _, m := range r.Rootfs { mounts = append(mounts, proc.Mount{ Type: m.Type, Source: m.Source, Target: m.Target, Options: m.Options, }) }
config := &proc.CreateConfig{ ID: r.ID, Bundle: r.Bundle, Runtime: r.Runtime, Rootfs: mounts, Terminal: r.Terminal, Stdin: r.Stdin, Stdout: r.Stdout, Stderr: r.Stderr, Checkpoint: r.Checkpoint, ParentCheckpoint: r.ParentCheckpoint, Options: r.Options, } rootfs := filepath.Join(r.Bundle, "rootfs") deferfunc(rootfs string) { if err != nil { if err2 := mount.UnmountAll(rootfs, 0); err2 != nil { log.G(ctx).WithError(err2).Warn("Failed to cleanup rootfs mount") } } }(rootfs) for _, rm := range mounts { m := &mount.Mount{ Type: rm.Type, Source: rm.Source, Options: rm.Options, } if err := m.Mount(rootfs); err != nil { returnnil, errors.Wrapf(err, "failed to mount rootfs component %v", m) } }
s.mu.Lock() defer s.mu.Unlock()
iflen(mounts) == 0 { rootfs = "" }
process, err := newInit( ctx, s.config.Path, s.config.WorkDir, s.config.RuntimeRoot, s.config.Namespace, s.config.Criu, s.config.SystemdCgroup, s.platform, config, rootfs, ) if err != nil { returnnil, errdefs.ToGRPC(err) } if err := process.Create(ctx, config); err != nil { returnnil, errdefs.ToGRPC(err) } // save the main task id and bundle to the shim for additional requests s.id = r.ID s.bundle = r.Bundle pid := process.Pid() s.processes[r.ID] = process return &shimapi.CreateTaskResponse{ Pid: uint32(pid), }, nil }
// Create the process with the provided config func(p *Init) Create(ctx context.Context, r *CreateConfig) error { var ( err error socket *runc.Socket )
// We only set up fifoFd if we're not doing a `runc exec`. The historic // reason for this is that previously we would pass a dirfd that allowed // for container rootfs escape (and not doing it in `runc exec` avoided // that problem), but we no longer do that. However, there's no need to do // this for `runc exec` so we just keep it this way to be safe. if err := c.includeExecFifo(cmd); err != nil { returnnil, newSystemErrorWithCause(err, "including execfifo in cmd.Exec setup") } return c.newInitProcess(p, cmd, messageSockPair, logFilePair) // 返回 initProcess,其中 cmd 为 runc init,并 c.initProcess = init }
func(p *initProcess) start() error { defer p.messageSockPair.parent.Close() err := p.cmd.Start() // 启动 runc init p.process.ops = p // close the write-side of the pipes (controlled by child) p.messageSockPair.child.Close() p.logFilePair.child.Close() if err != nil { p.process.ops = nil return newSystemErrorWithCause(err, "starting init process command") } // Do this before syncing with child so that no children can escape the // cgroup. We don't need to worry about not doing this and not being root // because we'd be using the rootless cgroup manager in that case. if err := p.manager.Apply(p.pid()); err != nil { return newSystemErrorWithCause(err, "applying cgroup configuration for process") } if p.intelRdtManager != nil { if err := p.intelRdtManager.Apply(p.pid()); err != nil { return newSystemErrorWithCause(err, "applying Intel RDT configuration for process") } } deferfunc() { if err != nil { // TODO: should not be the responsibility to call here p.manager.Destroy() if p.intelRdtManager != nil { p.intelRdtManager.Destroy() } } }()
if _, err := io.Copy(p.messageSockPair.parent, p.bootstrapData); err != nil { return newSystemErrorWithCause(err, "copying bootstrap data to pipe") } childPid, err := p.getChildPid() // 获取 child 的 pid if err != nil { return newSystemErrorWithCause(err, "getting the final child's pid from pipe") }
// Save the standard descriptor names before the container process // can potentially move them (e.g., via dup2()). If we don't do this now, // we won't know at checkpoint time which file descriptor to look up. fds, err := getPipeFds(childPid) if err != nil { return newSystemErrorWithCausef(err, "getting pipe fds for pid %d", childPid) } p.setExternalDescriptors(fds) // Do this before syncing with child so that no children // can escape the cgroup if err := p.manager.Apply(childPid); err != nil { // 这里设置调用具体的实现配置 cgroup return newSystemErrorWithCause(err, "applying cgroup configuration for process") } if p.intelRdtManager != nil { if err := p.intelRdtManager.Apply(childPid); err != nil { return newSystemErrorWithCause(err, "applying Intel RDT configuration for process") } } // Now it's time to setup cgroup namesapce if p.config.Config.Namespaces.Contains(configs.NEWCGROUP) && p.config.Config.Namespaces.PathOf(configs.NEWCGROUP) == "" { if _, err := p.messageSockPair.parent.Write([]byte{createCgroupns}); err != nil { return newSystemErrorWithCause(err, "sending synchronization value to init process") } }
// Wait for our first child to exit if err := p.waitForChildExit(childPid); err != nil { return newSystemErrorWithCause(err, "waiting for our first child to exit") }
deferfunc() { if err != nil { // TODO: should not be the responsibility to call here p.manager.Destroy() if p.intelRdtManager != nil { p.intelRdtManager.Destroy() } } }() if err := p.createNetworkInterfaces(); err != nil { // 创建网络接口 return newSystemErrorWithCause(err, "creating network interfaces") } if err := p.sendConfig(); err != nil { // 把配置发送给子进程 return newSystemErrorWithCause(err, "sending config to init process") } var ( sentRun bool sentResume bool )
ierr := parseSync(p.messageSockPair.parent, func(sync *syncT)error { switch sync.Type { case procReady: // set rlimits, this has to be done here because we lose permissions // to raise the limits once we enter a user-namespace if err := setupRlimits(p.config.Rlimits, p.pid()); err != nil { return newSystemErrorWithCause(err, "setting rlimits for ready process") } // call prestart hooks if !p.config.Config.Namespaces.Contains(configs.NEWNS) { // Setup cgroup before prestart hook, so that the prestart hook could apply cgroup permissions. if err := p.manager.Set(p.config.Config); err != nil { return newSystemErrorWithCause(err, "setting cgroup config for ready process") } if p.intelRdtManager != nil { if err := p.intelRdtManager.Set(p.config.Config); err != nil { return newSystemErrorWithCause(err, "setting Intel RDT config for ready process") } }
if p.config.Config.Hooks != nil { s, err := p.container.currentOCIState() if err != nil { return err } // initProcessStartTime hasn't been set yet. s.Pid = p.cmd.Process.Pid s.Status = "creating" for i, hook := range p.config.Config.Hooks.Prestart { if err := hook.Run(s); err != nil { return newSystemErrorWithCausef(err, "running prestart hook %d", i) } } } } // Sync with child. if err := writeSync(p.messageSockPair.parent, procRun); err != nil { return newSystemErrorWithCause(err, "writing syncT 'run'") } sentRun = true case procHooks: // Setup cgroup before prestart hook, so that the prestart hook could apply cgroup permissions. if err := p.manager.Set(p.config.Config); err != nil { return newSystemErrorWithCause(err, "setting cgroup config for procHooks process") } if p.intelRdtManager != nil { if err := p.intelRdtManager.Set(p.config.Config); err != nil { return newSystemErrorWithCause(err, "setting Intel RDT config for procHooks process") } } if p.config.Config.Hooks != nil { s, err := p.container.currentOCIState() if err != nil { return err } // initProcessStartTime hasn't been set yet. s.Pid = p.cmd.Process.Pid s.Status = "creating" for i, hook := range p.config.Config.Hooks.Prestart { if err := hook.Run(s); err != nil { return newSystemErrorWithCausef(err, "running prestart hook %d", i) } } } // Sync with child. if err := writeSync(p.messageSockPair.parent, procResume); err != nil { return newSystemErrorWithCause(err, "writing syncT 'resume'") } sentResume = true default: return newSystemError(fmt.Errorf("invalid JSON payload from child")) }
returnnil })
if !sentRun { return newSystemErrorWithCause(ierr, "container init") } if p.config.Config.Namespaces.Contains(configs.NEWNS) && !sentResume { return newSystemError(fmt.Errorf("could not synchronise after executing prestart hooks with container process")) } if err := unix.Shutdown(int(p.messageSockPair.parent.Fd()), unix.SHUT_WR); err != nil { return newSystemErrorWithCause(err, "shutting down init pipe") }
// Must be done after Shutdown so the child will exit and we can wait for it. if ierr != nil { p.wait() return ierr } returnnil }
// StartInitialization loads a container by opening the pipe fd from the parent to read the configuration and state // This is a low level implementation detail of the reexec and should not be consumed externally func(l *LinuxFactory) StartInitialization() (err error) { var ( pipefd, fifofd int consoleSocket *os.File envInitPipe = os.Getenv("_LIBCONTAINER_INITPIPE") envFifoFd = os.Getenv("_LIBCONTAINER_FIFOFD") envConsole = os.Getenv("_LIBCONTAINER_CONSOLE") )
// Get the INITPIPE. pipefd, err = strconv.Atoi(envInitPipe) if err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_INITPIPE=%s to int: %s", envInitPipe, err) }
var ( pipe = os.NewFile(uintptr(pipefd), "pipe") it = initType(os.Getenv("_LIBCONTAINER_INITTYPE")) ) defer pipe.Close()
// Only init processes have FIFOFD. fifofd = -1 if it == initStandard { if fifofd, err = strconv.Atoi(envFifoFd); err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_FIFOFD=%s to int: %s", envFifoFd, err) } }
if envConsole != "" { console, err := strconv.Atoi(envConsole) if err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_CONSOLE=%s to int: %s", envConsole, err) } consoleSocket = os.NewFile(uintptr(console), "console-socket") defer consoleSocket.Close() }
// clear the current process's environment to clean any libcontainer // specific env vars. os.Clearenv()
deferfunc() { // We have an error during the initialization of the container's init, // send it back to the parent process in the form of an initError. if werr := utils.WriteJSON(pipe, syncT{procError}); werr != nil { fmt.Fprintln(os.Stderr, err) return } if werr := utils.WriteJSON(pipe, newSystemError(err)); werr != nil { fmt.Fprintln(os.Stderr, err) return } }() deferfunc() { if e := recover(); e != nil { err = fmt.Errorf("panic from initialization: %v, %v", e, string(debug.Stack())) } }()
i, err := newContainerInit(it, pipe, consoleSocket, fifofd) if err != nil { return err }
// If Init succeeds, syscall.Exec will not return, hence none of the defers will be called. return i.Init() }
if err := setupNetwork(l.config); err != nil { // 根据 config 使用 netlink 进行配置 return err } if err := setupRoute(l.config.Config); err != nil { // 使用 netlink 设置 route - // signal, so we restore it here. if err := pdeath.Restore(); err != nil { return errors.Wrap(err, "restore pdeath signal") } // Compare the parent from the initial start of the init process and make // sure that it did not change. if the parent changes that means it died // and we were reparented to something else so we should just kill ourself // and not cause problems for someone else. if unix.Getppid() != l.parentPid { return unix.Kill(unix.Getpid(), unix.SIGKILL) } // Check for the arg before waiting to make sure it exists and it is // returned as a create time error. name, err := exec.LookPath(l.config.Args[0]) if err != nil { return err } // Close the pipe to signal that we have completed our init. l.pipe.Close() // Wait for the FIFO to be opened on the other side before exec-ing the // user process. We open it through /proc/self/fd/$fd, because the fd that // was given to us was an O_PATH fd to the fifo itself. Linux allows us to // re-open an O_PATH fd through /proc. // 看一下注释,这里利用了 fifo 的特点,等待 runc start 来开这个 fifo fd, err := unix.Open(fmt.Sprintf("/proc/self/fd/%d", l.fifoFd), unix.O_WRONLY|unix.O_CLOEXEC, 0) // 一起准备就绪过后他就会 hang 在这里 if err != nil { return newSystemErrorWithCause(err, "open exec fifo") } if _, err := unix.Write(fd, []byte("0")); err != nil { // 当用户调用 runc start 打开 fifo,就会执行到这里 return newSystemErrorWithCause(err, "write 0 exec fifo") } // Close the O_PATH fifofd fd before exec because the kernel resets // dumpable in the wrong order. This has been fixed in newer kernels, but // we keep this to ensure CVE-2016-9962 doesn't re-emerge on older kernels. // N.B. the core issue itself (passing dirfds to the host filesystem) has // since been resolved. // https://github.com/torvalds/linux/blob/v4.9/fs/exec.c#L1290-L1318 unix.Close(l.fifoFd) // Set seccomp as close to execve as possible, so as few syscalls take // place afterward (reducing the amount of syscalls that users need to // enable in their seccomp profiles). if l.config.Config.Seccomp != nil && l.config.NoNewPrivileges { if err := seccomp.InitSeccomp(l.config.Config.Seccomp); err != nil { return newSystemErrorWithCause(err, "init seccomp") } } if err := syscall.Exec(name, l.config.Args[0:], os.Environ()); err != nil { // 这里 swap 用户的进程了 return newSystemErrorWithCause(err, "exec user process") } returnnil }
func(c *linuxContainer) exec() error { path := filepath.Join(c.root, execFifoFilename) pid := c.initProcess.pid() blockingFifoOpenCh := awaitFifoOpen(path) for { select { case result := <-blockingFifoOpenCh: return handleFifoResult(result)
case <-time.After(time.Millisecond * 100): stat, err := system.Stat(pid) if err != nil || stat.State == system.Zombie { // could be because process started, ran, and completed between our 100ms timeout and our system.Stat() check. // see if the fifo exists and has data (with a non-blocking open, which will succeed if the writing process is complete). if err := handleFifoResult(fifoOpen(path, false)); err != nil { return errors.New("container process is already dead") } returnnil } } } }