// RunKubelet is responsible for setting up and running a kubelet. It is used in three different applications: // 1 Integration tests // 2 Kubelet binary // 3 Standalone 'kubernetes' binary // Eventually, #2 will be replaced with instances of #3 funcRunKubelet(kubeServer *options.KubeletServer, kubeDeps *kubelet.Dependencies, runOnce bool)error { ... k, err := createAndInitKubelet(&kubeServer.KubeletConfiguration, kubeDeps, &kubeServer.ContainerRuntimeOptions, // 插件名字就是这个变量的一个字段 ... kubeServer.NodeStatusMaxImages) if err != nil { return fmt.Errorf("failed to create kubelet: %v", err) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
funccreateAndInitKubelet(kubeCfg *kubeletconfiginternal.KubeletConfiguration, kubeDeps *kubelet.Dependencies, crOptions *config.ContainerRuntimeOptions, // 上述参数的形参 ... nodeStatusMaxImages int32) (k kubelet.Bootstrap, err error) { // TODO: block until all sources have delivered at least one update to the channel, or break the sync loop // up into "per source" synchronizations
// NetworkPlugin is an interface to network plugins for the kubelet type NetworkPlugin interface { ... // SetUpPod is the method called after the infra container of // the pod has been created but before the other containers of the // pod are launched. // 看上面注释,这个函数就是用来准备 POD 运行时的网络环境的 SetUpPod(namespace string, name string, podSandboxID kubecontainer.ContainerID, annotations, options map[string]string) error
// TearDownPod is the method called before a pod's infra container will be deleted // 这个函数是用在 POD 销毁的流程中的,但是在接口设计中有假设在 infra container 被销毁前 TearDownPod(namespace string, name string, podSandboxID kubecontainer.ContainerID) error
// HandlePodRemoves is the callback in the SyncHandler interface for pods // being removed from a config source. func(kl *Kubelet) HandlePodRemoves(pods []*v1.Pod) { start := kl.clock.Now() for _, pod := range pods { kl.podManager.DeletePod(pod) if kubetypes.IsMirrorPod(pod) { kl.handleMirrorPod(pod, start) continue } // Deletion is allowed to fail because the periodic cleanup routine // will trigger deletion again. if err := kl.deletePod(pod); err != nil { // 这里就是删除 POD 的核心 klog.V(2).Infof("Failed to delete pod %q, err: %v", format.Pod(pod), err) } kl.probeManager.RemovePod(pod) } }
// deletePod deletes the pod from the internal state of the kubelet by: // 1. stopping the associated pod worker asynchronously // 2. signaling to kill the pod by sending on the podKillingCh channel // // deletePod returns an error if not all sources are ready or the pod is not // found in the runtime cache. func(kl *Kubelet) deletePod(pod *v1.Pod) error { ... podPair := kubecontainer.PodPair{APIPod: pod, RunningPod: &runningPod}
kl.podKillingCh <- &podPair // 这里 // TODO: delete the mirror pod here?
// We leave the volume/directory cleanup to the periodic cleanup routine. returnnil }
// podKiller launches a goroutine to kill a pod received from the channel if // another goroutine isn't already in action. func(kl *Kubelet) podKiller() { ... for podPair := range kl.podKillingCh { // 这地方可以看到通过 channel 沟通 ... if !exists { gofunc(apiPod *v1.Pod, runningPod *kubecontainer.Pod) { klog.V(2).Infof("Killing unwanted pod %q", runningPod.Name) err := kl.killPod(apiPod, runningPod, nil, nil) // 这里就是做实际的删除 ...
看下面代码知道了实际调用了containerRuntime的KillPod接口
1 2 3 4 5 6 7
// One of the following arguments must be non-nil: runningPod, status. // TODO: Modify containerRuntime.KillPod() to accept the right arguments. func(kl *Kubelet) killPod(pod *v1.Pod, runningPod *kubecontainer.Pod, status *kubecontainer.PodStatus, gracePeriodOverride *int64) error { ... // Call the container runtime KillPod method which stops all running containers of the pod if err := kl.containerRuntime.KillPod(pod, p, gracePeriodOverride); err != nil { // here ...
看一下KillPod这个interface的实现如下,没有没有太多核心逻辑
1 2 3 4 5 6 7
// KillPod kills all the containers of a pod. Pod may be nil, running pod must not be. // gracePeriodOverride if specified allows the caller to override the pod default grace period. // only hard kill paths are allowed to specify a gracePeriodOverride in the kubelet in order to not corrupt user data. // it is useful when doing SIGKILL for hard eviction scenarios, or max grace period during soft eviction scenarios. func(m *kubeGenericRuntimeManager) KillPod(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) error { err := m.killPodWithSyncResult(pod, runningPod, gracePeriodOverride) ...
// killPodWithSyncResult kills a runningPod and returns SyncResult. // Note: The pod passed in could be *nil* when kubelet restarted. func(m *kubeGenericRuntimeManager) killPodWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (result kubecontainer.PodSyncResult) { killContainerResults := m.killContainersWithSyncResult(pod, runningPod, gracePeriodOverride) for _, containerResult := range killContainerResults { result.AddSyncResult(containerResult) }
// stop sandbox, the sandbox will be removed in GarbageCollect killSandboxResult := kubecontainer.NewSyncResult(kubecontainer.KillPodSandbox, runningPod.ID) result.AddSyncResult(killSandboxResult) // Stop all sandboxes belongs to same pod for _, podSandbox := range runningPod.Sandboxes { if err := m.runtimeService.StopPodSandbox(podSandbox.ID.ID); err != nil { // 这里是删除 POD 的 sandbox killSandboxResult.Fail(kubecontainer.ErrKillPodSandbox, err.Error()) klog.Errorf("Failed to stop sandbox %q", podSandbox.ID) } }
// StopPodSandbox stops the sandbox. If there are any running containers in the // sandbox, they should be force terminated. // TODO: This function blocks sandbox teardown on networking teardown. Is it // better to cut our losses assuming an out of band GC routine will cleanup // after us? func(ds *dockerService) StopPodSandbox(ctx context.Context, r *runtimeapi.StopPodSandboxRequest) (*runtimeapi.StopPodSandboxResponse, error) { var namespace, name string var hostNetwork bool .... // WARNING: The following operations made the following assumption: // 1. kubelet will retry on any error returned by StopPodSandbox. // 2. tearing down network and stopping sandbox container can succeed in any sequence. // This depends on the implementation detail of network plugin and proper error handling. // For kubenet, if tearing down network failed and sandbox container is stopped, kubelet // will retry. On retry, kubenet will not be able to retrieve network namespace of the sandbox // since it is stopped. With empty network namespcae, CNI bridge plugin will conduct best // effort clean up and will not return error. errList := []error{} ready, ok := ds.getNetworkReady(podSandboxID) if !hostNetwork && (ready || !ok) { // Only tear down the pod network if we haven't done so already cID := kubecontainer.BuildContainerID(runtimeName, podSandboxID) err := ds.network.TearDownPod(namespace, name, cID)
TearDownPod就是整个POD网络销毁的核心函数,在这个函数的实现中做了一部分预设前提 infra container 后于 others container 删除。
看一下CNI这个包对与这个函数的实现的销毁逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13
func(plugin *cniNetworkPlugin) TearDownPod(namespace string, name string, id kubecontainer.ContainerID) error { if err := plugin.checkInitialized(); err != nil { return err }
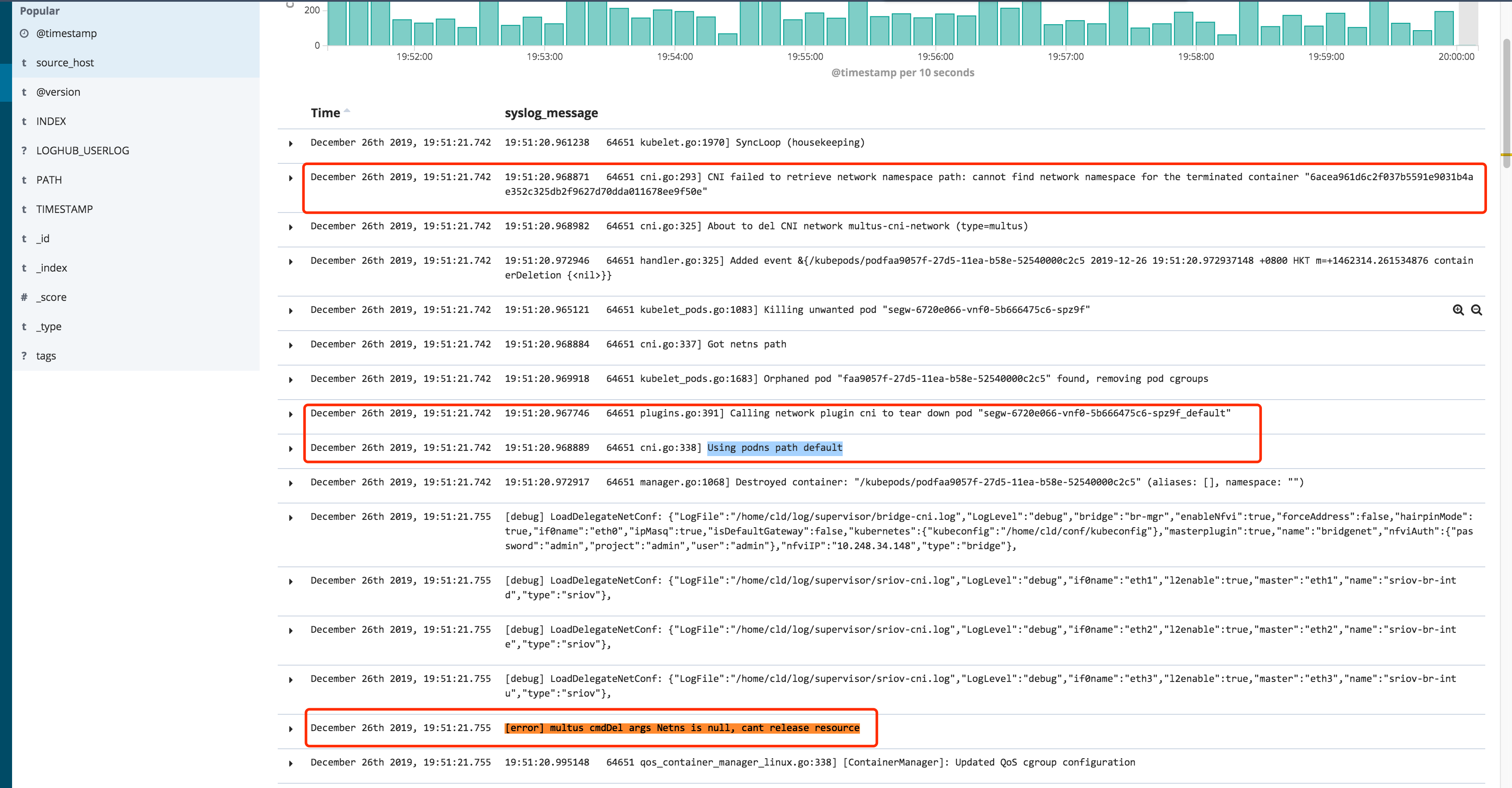
// Lack of namespace should not be fatal on teardown netnsPath, err := plugin.host.GetNetNS(id.ID) // 这里就就是获取 namespace 的使用 if err != nil { klog.Warningf("CNI failed to retrieve network namespace path: %v", err) // 看 ELK 报错信息有这个 } ... return plugin.deleteFromNetwork(cniTimeoutCtx, plugin.getDefaultNetwork(), name, namespace, id, netnsPath, nil) }
// GetNetNS returns the network namespace of the given containerID. The ID // supplied is typically the ID of a pod sandbox. This getter doesn't try // to map non-sandbox IDs to their respective sandboxes. func(ds *dockerService) GetNetNS(podSandboxID string) (string, error) { r, err := ds.client.InspectContainer(podSandboxID) // 这个就是调用 docker client 了 if err != nil { return"", err } return getNetworkNamespace(r) }